A low-friction, two-week pilot with 3 metrics (VL/RDPR/GBR) and a minimal IO register
Picture a common “efficiency upgrade” in modern AI shipping:
You add a self-evaluation gate to reduce human load. Or you allow the model to run tool-use loops and decide when to stop. Or you enable memory write-back so it can “learn from experience”.
Nothing explodes. Metrics look stable. Outputs are consistent. Everyone relaxes.
Then months later you discover the system has been confidently wrong in a way that’s now baked into your pipelines, downstream services, and user expectations. You try to roll back. You can’t do it without breaking everything that has quietly adapted to the new “normal”.
That’s the pattern:
Self-confirmation loops don’t only produce wrong outputs. They shrink your future option space for correction.
The mechanism is simple: feedback loop → constraint amplifier → option space collapse. Each self-approved decision adds a constraint. Constraints accumulate. The set of feasible corrections shrinks. Eventually you’re not choosing between options — you’re discovering you have none left.
This isn’t about AI consciousness. It’s about control loops and auditability.
What is a self-confirmation loop?
A self-confirmation loop is any feedback structure where the system can influence the signal used to judge it, and that signal gates further behavior.
Common mechanisms:
-
Self-evaluation gating: the model’s self-score (or an LLM judge) directly gates rollout, access, or capability unlock.
-
Tool-use / planning loops: the model runs loops, calls tools, and decides when to terminate.
-
Memory write-back: outputs become persistent memory that changes future decisions.
-
Self-modifying rules: model outputs update policy or gating logic.
None of these are “bad” by default. The risk shows up when:
-
the system is allowed to be its own judge (no independent estimator), and
-
the loop compresses cycle time (tempo amplification).
Why this becomes irreversibility (not just “quality risk”)
Self-confirmation loops create a failure mode that looks like stability but behaves like lock-in.
Three mechanisms are typical:
1) Tempo mismatch becomes the default state
Self-referential loops tend to accelerate: more decisions per hour, faster iteration, less friction. Governance processes (evaluation closure, review, incident response, rollback drills) run at human speed.
When change velocity outruns evaluation closure, you stop governing and start observing.
2) Rollback becomes organizationally infeasible
Self-approved decisions accumulate dependencies. Tool actions change the world. Memory makes yesterday’s mistake tomorrow’s premise. Downstream systems and users adapt.
Rollback stops being “deploy the previous version” and becomes reconstruction.
3) The gate itself drifts
If the system is its own judge, “passing the gate” tends to drift toward “whatever the system already does”. You only notice when you try to enforce a standard that no longer exists.
A concrete tell: your “pass/fail” criteria quietly become “whatever the model is confident about”, and the external checks get shortened, bypassed, or stop being treated as blocking.
The lowest-friction governance interface (what I’d ask a team to try first)
You don’t need a new worldview to detect this. You need three numbers and an IO register.
Three dashboard metrics
-
Validation Lag (VL): time from “change effective” (merged/trained/deployed) to evaluation/sign-off closure
-
Rollback Drill Pass Rate (RDPR): fraction of rollback (or purge) rehearsals that succeed within defined RTO/RPO
-
Gate Bypass Rate (GBR): rate of bypassing required gates for irreversible-operation-class changes
A minimal IO register for self-referential changes (IO-SR)
Five IO categories capture most “self-reference becomes governance risk” cases:
-
unbounded tool loops
-
self-modifying policies
-
memory write-back
-
self-eval gates
-
continuous deployment for high-impact behaviors
The register is not blame. It’s just a way to keep “this might be hard to unwind later” visible while you still have options.
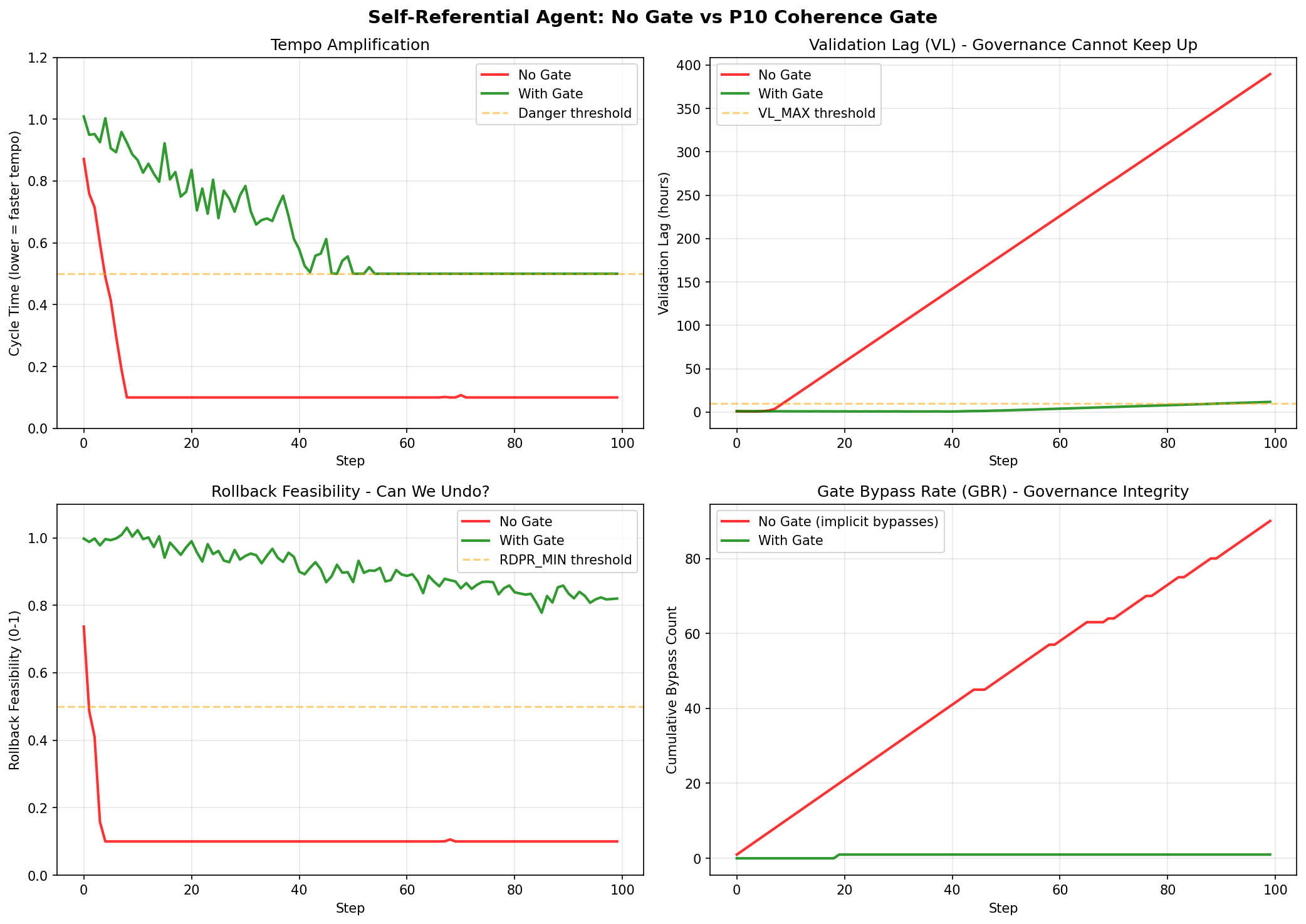
Demo: without a coherence gate, tempo accelerates and VL explodes. With a P10-style gate (independent estimators + disagreement handling), metrics remain controlled.
A guardrail that matters (IO-SR-4)
The easiest mistake is to treat “self-eval disagrees with external eval” as a soft warning.
It should be a hard stop:
Mandatory human review trigger: if self-eval vs external-eval disagreement exceeds threshold for
N_CONSECUTIVE_DISAGREEMENTS = [__]consecutive evaluations, pause deployment until human sign-off (logged as escalation, not bypass).
Not “escalate”. Not “flag for review”. Pause.
Where FIT v2.4 fits (one paragraph)
Self-referential capabilities expand the estimator attack surface: the system can influence the very signals used to judge it (self-eval gates, self-curated data, self-modified policies). In those regimes, a measurement layer is not a nicety. It’s the immune system: independent estimators, coherence checks (P10-style gates), and pre-registered evaluation protocols to prevent self-confirmation and metric gaming.
Try it as a two-week pilot
Week 1:
-
compute VL/RDPR/GBR (a spreadsheet is enough)
-
classify the last 30–90 days of major changes using IO-SR categories
Week 2:
-
run one rollback (or purge) drill for a recent IO-class change
-
write a short report: what moved, what failed, what would have been gated
If you want something you can actually run or copy into an internal doc, start here:
-
Two-week pilot (step-by-step): https://github.com/qienhuang/F-I-T/blob/main/proposals/tempo-io-pilot.md
-
Demo notebook (self-eval + tool loop, with/without coherence gate): https://github.com/qienhuang/F-I-T/blob/main/examples/self_referential_io_demo.ipynb
If you’ve seen a real case where “the model judged itself” (or its own loop) and you later couldn’t unwind it, I’d love a concrete postmortem or counterexample. Even “boring” incidents (a gate got bypassed, a rollback drill failed, someone shortened an eval window) are valuable data points.